8. Structures¶
8.1. Compound values¶
Most of the data types we have been working with represent a single value - an
integer, a floating-point number, a boolean value. strings are different
in the sense that they are made up of smaller pieces, the characters. Thus,
strings are an example of a compound type.
Depending on what we are doing, we may want to treat a compound type as a single thing (or object), or we may want to access its parts (or instance variables). This ambiguity is useful.
It is also useful to be able to create your own compound values. C++ provides two mechanisms for doing that: structures and classes. We will start out with structures and get to classes in the Classes and invariants chapter.
8.2. Point objects¶
As a simple example of a compound structure, consider the concept of a mathematical point. At one level, a point is two numbers (coordinates) that we treat collectively as a single object. In mathematical notation, points are often written in parentheses, with a comma seperating the coordinates. For example, \((0, 0)\) indicates the origin, and \((x, y)\) indicates the point \(x\) units to the right and \(y\) units up from the origin.
A natural way to represent a point in C++ is with two doubless. The
question, then, is how to group these two values into a compound object, or
structure. The answer is a struct definition:
struct Point {
double x, y;
};
struct definitions appear outside of any function definition, usually at
the beginning of the program (after the include statements).
This definition indicates that there are two elements in this structure, named
x and y. These elements are called instance variables, for reasons
we will explain a little later.
It is a common error to leave off the semi-colon at the end of a structure definition. It might seem odd to put a semi-colon after a curly brace, but you’ll get used to it.
Once you have defined the new structure, you can create variables with that type:
Point blank;
blank.x = 3.0;
blank.y = 3.0;
The first line is a conventional variable declaration: blank has type
Point. The next two lines initialize the instance variables of the
structure. The dot notation used here similar to the syntax for invoking
a function on an object, as in the fruit.length() we saw in the
Length section of the previous chapter. Of course, one
difference is that function names are always followed by an argument list,
even if it is empty.
The result of these arguments is shown in the following state diagram:
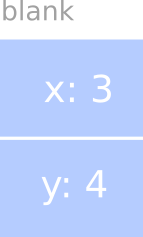
As usual, the name of the variable blank appears outside the box and its
value appears inside the box. In this case, the value is a compound object
with two named instance variables.
8.3. Accessing instance variables¶
You can read the values of an instance variable using the same syntax we used to write them:
int x = blank.x;
The expression blank.x means “go to the object named blank and get the
value of x.” In this case we assign that value to a local variable named
x. Notice that there is no conflict between the local variable named x
and the instance variable named x. The purpose of the dot notation is to
identify which variable you are referring to unambigously.
You can use dot notation as part of any C++ expression, so the following are legal.
cout << "(" << blank.x << ", " << blank.y << ")" << endl;
double distance = blank.x * blank.x + blank.y * blank.y;
The first line outputs (3, 4); the second computes the value 25.
8.4. Operations on structures¶
Most of the operators we have been using on other types, like mathematical
operators (+, %, etc.) and comparision operators (==, >, etc.),
do not work on structures. Actually, it is possible to define the meaning of
these operators for the new type, but we won’t do that in this book.
Note
Defining the meaning of built-in operators for new user defined types is called operator overloading. Not all programming languages support this feature, but C++ does.
On the other hand, the assignment operator does work for structures. It can be used in two ways: to initialize the instance variables of a structure or to copy the instance variables from one structure to another of the same type. An initialization looks like this:
Point blank = {3.0, 4.0};
The values in the curly braces get assigned to the instance variables of the
structure one by one, in order. So in this case, x gets the first value
and y gets the second.
Unfortunately, this syntax can only be used on an initialization, not in an assignment statement. So the following is illegal.
Point blank;
blank = {3.0, 4.0} // WRONG!
You might wonder why this perfectly reasonable statement should be illegal, and there is no good answer. We’re sorry.
On the other hand, it is legal to assign one structure variable to another of the same type. For example:
Point p1 = {3.0, 4.0};
Point p2 = p1;
cout << "(" << p2.x << ", " << p2.y << ")" << endl;
The output of this program is (3, 4).
8.5. Structues as parameters¶
You can pass structures as parameters in the usual way. For example:
void print_point(Point p)
{
cout << "(" << p.x << ", " << p.y << ")" << endl;
}
print_point takes a point as an argument and outputs it in the standard
format. If you call print_point(blank), it will output (3, 4).
As a second example, we can rewrite the distance function from the
Program development section of chapter 5 so that it has two
Point parameters instead of four doubles.
double distance(Point p1, Point p2)
{
double dx = p2.x - p1.x;
double dy = p2.y - p1.y;
return sqrt(dx*dx + dy*dy);
}
Remember to include the cmath library for sqrt.
8.6. Pass by value¶
When you pass a structure as an argument, remember that the argument and the
parameter are not the same variable. Instead, there are two variables (one in
the caller and one in the callee) that have the same value, at least initially.
For example, when we call print_point, the stack diagram looks like this:
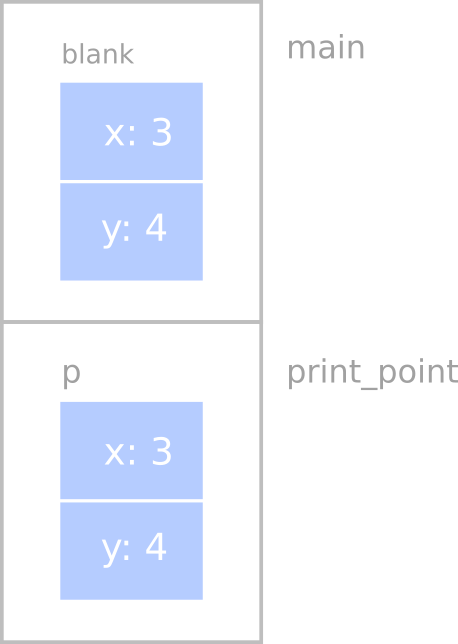
If print_point happened to change one of the instance variables of p, it
would have no effect on blank. Of course, there is no reason in this case
for print_point to modify its parameter.
This kind of parameter passing is called pass by value because it is the value of the structure (or other type) that gets passed to the function.
8.7. Pass by reference¶
An alternative parameter passing mechanism that is available in C++ is called pass by reference. This mechanism makes it possible to pass a structure to a procedure and modify it.
For example, you can reflect a point around the 45-degree line by swapping the
two coordinates. The most obvious (but incorrect) way to write a reflect
function is something like this:
void reflect(Point p) // WRONG!
{
double temp = p.x;
p.x = p.y;
p.y = temp;
}
But this won’t work, because the changes we make in reflect will have no
effect on the caller.
Instead, we have to specify that we want to pass the parameter by reference.
We do that by adding an ampersand (&) to the parameter declaration:
void reflect(Point& p)
{
double temp = p.x;
p.x = p.y;
p.y = temp;
}
Now we can call the function in the usual way:
print_point(blank);
reflect(blank);
print_point(blank);
The output of this code is as expected:
(3, 4)
(4, 3)
Here’s how we would draw a stack diagram for this code:
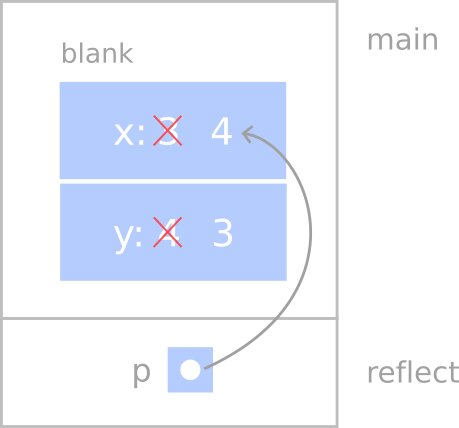
The parameter p is a reference to the structure named blank. The usual
representation for a reference is dot with an arrow that points to whatever the
reference refers to.
The important thing to see in this diagram is that any changes that reflect
makes to p will also change blank (since they are the same, not copies).
Passing structures by reference is more versatile than passing by value, because the callee can modify the structure. It is also faster, because the system does not have to copy the whole structure. On the other hand, is is less safe, since it is harder to keep track of what gets modified where. Nevertheless, in C++ programs, almost all structures are passed by reference almost all the time. We will follow that convention in this book.
8.8. Rectangles¶
Now let’s say that we want to create a structure to represent a rectangle. The question is, what information do we have to provide in order to specify a rectangle? To keep things simple let’s assume that the rectangle will be oriented vertically or horizontally, never at an angle.
There are a few possibilities: we could specify the center of the rectangle (two coordinates) and its size (width and height), or we could specify one of the corners and the size, or we could specify two opposing corners.
The most common choice in existing programs is to specify the upper left corner
of the rectangle and the size. To do that in C++, we will define a structure
that contains a Point and two doubles.
struct Rectangle {
Point corner;
double width, height;
};
Notice that one structure can contain another. In fact, this sort of thing is
quite common. Of course, this means that in order to create a Rectangle,
we have to create a Point first:
Point corner = {0.0, 0.0};
Rectangle box = {corner, 100.0, 200.0};
This code creates a new Point structure and initializes the instance
variables. The figure shows the effect of this assignment.

We can access the width and height in the usual way:
box.width += 50;
cout << box.height << endl;
In order to access the instance variables of corner, we can use a
temporary variable:
Point temp = box.corner;
double x = temp.x;
Alternatively, we can compose the two statements:
double x = box.corner.x;
It makes the most sense to read this statement from right to left: “Extract x from the corner of the box, and assign it to the local variable x.”
While on the subject of composition, we should point out that you can, in fact,
create the Point and the Rectangle at the same time:
Rectangle box = {{0.0, 0.0}, 100.0, 200.0};
The innermost curly braces are the coordinates of the corner point; together
they make up the first of the three values that go into the new Rectangle.
This statement is an example of nested structure.
8.9. Structures as return types¶
You can write functions that return structures. For example, find_center
takes a Rectangle as an argument and returns a Point that contains the
coordinates of the center of the Rectangle:
Point find_center (Rectangle& box)
{
double x = box.corner.x + box.width/2;
double y = box.corner.y + box.height/2;
Point result = {x, y};
return result;
}
To call this function, we have to pass a box as an argument (notice that it is
being passed by reference), and assign the return value to a Point
variable:
Rectangle box = {{0, 0}, 100, 200};
Point center = find_center(box);
print_point(center);
The output of this program is (50, 100).
8.10. Passing other types by reference¶
It’s not just structures that can be passed by reference. All the other types we’ve seen can too. For example, to swap two integers, we could write something like:
void swap(int& x, int& y)
{
int temp = x;
x = y;
y = temp;
}
We would call this function in the usual way:
int i = 7;
int j = 9;
swap(i, j);
cout << i << j << endl;
The output of this program is 97. Draw a stack diagram for this program to
convince yourself this is true. If the parameters x and y were
declared as regular parameters (without the &s), swap would not work.
It would modify x and y and have no effect on i and j.
When people start passing things like integers by reference, they often try to use an expression as a reference argument. For example:
int i = 7;
int j = 9;
swap(i, j+1); // WRONG!
This is not legal because the expression j+1 is not a variable - it does
not occupy a location that the reference can refer to. It is a little tricky
to figure out exactly what kinds of expressions can be passed by reference.
For now a good rule of thumb is that reference arguments have to be variables.
8.11. Time¶
As a second example of a user-defined structure, we will define a type called
Time, which is used to record the time of day. The various pieces of
information that form a time are the hour, minute and second, so these will be
the instance variables of the structure.
The first step is to decide what type each instance variable should be. It
seems clear that hour and minute should be integers. Just to keep
things interesting, let’s make second a double, so we can record
fractions of a second.
Here’s what the structure definition looks like:
struct Time {
int hour, minute;
double second;
};
We can create a Time object in the usual way:
Time time = {11, 59, 3.14159};
The state diagram for this object looks like this:

The word “instance” is sometimes used when we talk about objects, because every object is an instance (or example) of some type. The reason that instance variables are so-named is that every instance of a type has a copy of the instance variables for that type.
8.12. print_time¶
When we define a new type it is a good idea to write a function that displays the instance variables in a human-readable form. For example:
void print_time(Time& t) {
cout << t.hour << ":" << t.minute << ":" << t.second << endl;
}
The output of this function, if we pass time as an argument, is
11:59:3.14159.
8.13. Functions for objects¶
In the next few sections, we will demonstrate several possible interfaces for functions that operate on objects. For some operations, you will have a choice of several possible interfaces, so you should consider the pros and cons of each of these:
- pure function
Takes objects and/or basic types as arguments but does not modify the objects. The return value is either a basic type or a new object created inside the function.
- modifier
Takes objects as parameters and modifies some or all of them. Often returns void.
- fill-in function
One of the parameters is an “empty” object that gets filled in by the function. Technically, this is a type of modifier.
8.14. Pure functions¶
A function is considered a pure function if the result depends only on the arguments, and it has no side effects like modifying and argument or outputting something. The only result of calling a pure function is the return value.
One example is after, which compares two Times and returns a bool
that indicates whether the first operand comes after the second:
bool after(Time& time1, Time& time2)
{
if (time1.hour > time2.hour) return true;
if (time1.hour < time2.hour) return false;
if (time1.minute > time2.minute) return true;
if (time1.minute > time2.minute) return false;
if (time1.second > time2.second) return true;
return false;
}
What is the result of this function if the two times are equal? Does this seem like the appropriate result for this function? If you were writing documentation for this function, would you mention that case specifically?
A second exampel is add_time, which calculates the sum of two times. For
example, if it is 9:14:30, and your breadmaker takes 3 hours and 35 minutes,
you could use add_time to figure out when the bread will be done.
Here is a rough draft of this function that is not quite right:
Time add_time(Time& t1, Time& t2)
{
Time sum;
sum.hour = t1.hour + t2.hour;
sum.minute = t1.minute + t2.minute;
sum.second = t1.second + t2.second;
return sum;
}
Here is an example of how to use this function. If current_time contains the
current time and bread_time it takes for your breadmaker to make bread, then
you could use add_time to figure out when the bread will be done.
Time current_time = {9, 14, 30.0};
Time bread_time = {3, 35, 0.0};
Time done_time = add_time(current_time, bread_time);
print_time(done_time);
The output of this program is 12:49:30, which is correct. On the other
hand, there are cases where the result is not correct. Can you think of one?
The problem is that this function does not deal with cases where the number of seconds or minutes adds up to more than 60. When that happens we have to carry the extra seconds into the minutes column, or extra minutes into the hours column.
Here’s a second, corrected version of this function.
Time add_time(Time& t1, Time& t2)
{
Time sum;
sum.hour = t1.hour + t2.hour;
sum.minute = t1.minute + t2.minute;
sum.second = t1.second + t2.second;
if (sum.second >= 60) {
sum.second -= 60;
sum.minute += 1;
}
if (sum.minute >= 60) {
sum.minute -= 60;
sum.hour += 1;
}
return sum;
}
Although it’s correct, it’s starting to get big. Later, we will suggest an alternate approach to this problem that will be much shorter.
This code demonstrates two operators we have not seen before, += and
-=. These operators provide a consise way to increment and decrement
variables. For example, the statement sum.second -= 60; is equivalent to
sum.second = sum.second - 60;
8.15. const parameters¶
You might have noticed that the parameters for after and add_time are
being passed by reference. Since these are pure functions, they do not modify
the parameters they receive, so we could just as well have passed them by
value.
The advantage of passing by value is that the calling function and the callee are appropriately encapsulated - it is not possible for a change in one to affect the other, except by affecting the return value. On the other hand, passing by reference usually is more efficient, because it avoids copying the argument.
There is a nice feature in C++, called const, that can make reference
parameters just as safe as value parameters.
Declaring a parameter a constant reference parameter will cause a compiler error, or at least a warning, if you try to change the parameter value inside the function.
The syntax looks like this:
void print_time (const Time& time) ...
Time add_time(const Time& t1, const Time& t2) ...
8.16. Modifiers¶
Of course, sometimes you want to modify one of the arguments. Functions that do are called modifiers.
As an example of a modifier, consider increment, which adds a given number
of seconds to a Time object. Again, a rough draft of this function looks
like:
void increment(Time& time, double secs)
{
time.second += secs;
while (time.second >= 60.0) {
time.second -= 60.0;
time.minute += 1;
}
while (time.minute >= 60) {
time.minute -= 60;
time.hour += 1;
}
}
This solution is correct, but not very efficient. We’ll leave it as an exercise to write a better one.
8.17. Fill-in functions¶
Occasionally you will see functions like add_time written with a different
interface (different arguments and return values). Instead of creating a new
object every time add_time is called, we could require the caller to provide
an “empty” object where add_time can store the result. Compare the following
with the previous version:
void add_time_fill(const Time& t1, const Time& t2, Time& sum)
{
sum.hour = t1.hour + t2.hour;
sum.minute = t1.minute + t2.minute;
sum.second = t1.second + t2.second;
if (sum.second >= 60) {
sum.second -= 60;
sum.minute += 1;
}
if (sum.minute >= 60) {
sum.minute -= 60;
sum.hour += 1;
}
}
One advantage of this approach is that the caller has the option of reusing the same object repeatedly to perform a series of additions. This can be slightly more effecient, although it can be confusing enough to cause subtle errors. For the vast majority of programming, it is worth spending a little run time to avoid a lot of debugging time.
Notice that the first two parameters can be declared const, but the third
cannot.
8.18. Which is best?¶
Anything that be done with modifiers and fill-in functions can also be done with pure functions. In fact, there are programming languages, called functional programming languages, that only allow pure functions. Some programmers believe that programs that use pure functions are faster to develop and less error-prone than programs that use modifiers. Nevertheless, there are times when modifiers are convenient, and cases where functional programs are less efficient.
In general, we recommend that you write pure functions whenever it is reasonable to do so, and resort to modifiers only if there is a compelling advantage. This approach might be called a functional programming style., that only allow pure functions. Some programmers believe that programs that use pure functions are faster to develop and less error-prone than programs that use modifiers. Nevertheless, there are times when modifiers are convenient, and cases where functional programs are less efficient.
In general, we recommend that you write pure functions whenever it is reasonable to do so, and resort to modifiers only if there is a compelling advantage. This approach might be called a functional programming style., that only allow pure functions. Some programmers believe that programs that use pure functions are faster to develop and less error-prone than programs that use modifiers. Nevertheless, there are times when modifiers are convenient, and cases where functional programs are less efficient.
In general, we recommend that you write pure functions whenever it is reasonable to do so, and resort to modifiers only if there is a compelling advantage. This approach might be called a functional programming style., that only allow pure functions. Some programmers believe that programs that use pure functions are faster to develop and less error-prone than programs that use modifiers. Nevertheless, there are times when modifiers are convenient, and cases where functional programs are less efficient.
In general, we recommend that you write pure functions whenever it is reasonable to do so, and resort to modifiers only if there is a compelling advantage. This approach might be called a functional programming style.
8.19. Incremental development versus planning¶
In this chapter we have demonstrated an approach to program development we refer to as rapid prototyping with iterative improvement. In each case, we wrote a rough draft (or prototype) that performed the basic calculation, and then tested it on a few cases, correcting flaws as we found them.
Although this approach can be effective, it can lead to code that is unnecessarily complicated - since it deals with many special cases - and unreliable - since it is hard to know if you have found all the errors.
An alternative is high-level planning, in which a little insight into the
problem can make the programming much easier. In this case the insight is that
a Time is really a three-digit number in base 60! The second is the
“ones column,” the minute is the “60s column,” and the hour is the
“3600’s column.”
When we wrote add_time and increment, we were effectively doing
addition in base 60, which is why we had to “carry” from one column to the
next.
Thus an alternative approach to the whole problem is to convert Times
into doubles and take advantage of the fact that the computer already
knows how to do arithmetic with doubles. Here is a function that converts
a Time into a double:
double convert_to_seconds(const Time& t)
{
int minutes = t.hour * 60 + t.minute;
double seconds = minutes * 60 + t.second;
return seconds;
}
Now all we need is a way to convert from a double to a Time object:
Time make_time(double secs)
{
Time time;
time.hour = int(secs / 3600.0);
secs -= time.hour * 3600.0;
time.minute = int(secs / 60.0);
secs -= time.minute * 60;
time.second = secs;
return time;
}
You might have to think a bit to convince yourself that the technique we are
using to convert from one base to another is correct. Assuming you are
convinced, we can use these functions to rewrite add_time:
Time add_time(const Time& t1, const Time& t2)
{
return make_time(convert_to_seconds(t1) + convert_to_seconds(t2));
}
This is much shorter than the original version, and it is much easier to demonstrate that is is correct (assuming, as usual, that the functions it calls are correct).
8.20. Generalization¶
In some ways converting from base 60 to base 10 and back is harder than just dealing with times. Base conversion is more abstract; our intuition for dealing with times is better.
But if we have the insight to treat times as base 60 numbers, and make the
investment of writing the conversion functions (convert_to_seconds and
make_time), we get a program that is shorter, easier to read and debug, and
more reliable.
It is also easier to add more features later. For example, imagine subtracting
two Times to find the duration between them. The naive approach would be
to implement substraction with borrowing. Using the conversion functions would
be much easier and more likely to be correct.
Ironically, sometimes making a problem harder (more general) makes it easier (fewer special cases, fewer opportunities for error).
8.21. Algorithms¶
When you write a general solution for a class of problems, as opposed to a specific solution to a single problem, you have written an algorithm. We mentioned this word in The way of the program chapter, but we did not define it carefully. It is not easy to define, so we will try a couple of approaches.
First, consider something that is not an algorithm. When you learned to multiply single-digit numbers, you probably memorized the multiplication table. In effect, you memorized 100 specific solutions. That kind of knowledge is not really algorithmic.
But if you were “lazy”, you probably cheated by learning a few tricks. For example, to find the product of \(n\) and 9, you can write \(n - 1\) as the first digit and \(10 - n\) as the second digit. This trick is a general solution for multiplying any single-digit number by 9. That’s an algorithm!
Similarly, the techniques you learned for addition with carrying, subtraction with borrowing, and long division are all algorithms. One of the characteristics of algorithms is that they do not require any intelligence to carry out. They are mechanical processes in which each step follows from the last according to a simple set of rules.
In our opinion, it is embarrassing that humans spend so much time in school learning to execute algorithms that, quite literally, require no intelligence.
On the other hand, the process of designing algorithms is interesting, intellectually challenging, and a central part of what we call programming.
Some of the things that people do naturally, without difficulty or concious thought, are the most difficult to express algorithmically. Understanding natural language is a good example. We all do it, but it is only recently that the interdisciplinary field of natural language processing has reached the point where programs like ChatGPT have become possible for computers.
Later in this book, you will have the opportunity to design algorithms for a variety of problems, including some of the more interesting, clever, and useful algorithms computer science has produced.
8.22. Glossary¶
- constant reference parameter¶
A parameter that is passed by reference but that cannot be modified.
- fill-in function¶
A function that takes an “empty” object as a parameter and fills in its instance variables instead of generating a return value.
- functional programming style¶
A style of program design in which the majority of functions are pure.
- instance¶
An example from a category. Your cat is an instance of the category “feline things”. Every object is the instance of some type.
- instance variable¶
One of the named pieces of data that make up a structure.
- modifier¶
A function that changes one or more of the objects it recieves as parameters, and usually returns
void.- pass by value¶
A method of parameter passing in which the value provided as an argument is copied into the corresponding parameter, but the parameter and the argument occupy distinct locations.
- pass by reference¶
A method of parameter passing in which the parameter is a reference to the argument variable. Changes to the parameter also effect the argument variable.
- pure function¶
A function whose result depends only on its parameters, and that has no other effects other than returning a value.
- reference¶
A value that indicates or refers to a variable or structure. In a state diagram, a reference appears as an arrow.
- structure¶
A collection of data grouped together and treated as a single object.