3. Functions¶
3.1. Floating-point¶
In the last chapter we had some problems dealing with numbers that were not
integers. We worked around the problem by measuring percentages instead of
fractions, but a more general solution is to use floating-point numbers,
which can represent fractions as well as integers. In C++, there are two
floating-point types, called float and double. In this book we will
usually use doubles.
You can create floating-point variables and assign values to them using the same syntax we used for the other types. For example:
double pi;
pi = 3.14159;
It is also legal to declare a variable and assign a value to it at the same time:
double pi = 3.14159;
In fact, this systax is quite common. A combined declaration and assignment is sometimes called an initialization.
Although floating-point numbers are useful, they are often a source of confusion because there seems to be an overlap between integers and floating-point numbers. For example, if you have a value 1, is that an integer, a floating-point number, or both?
C++ distinguishes the integer value 1 from the floating-point value 1.0, even though they seem to be the same number. They belong to different types, and strictly speaking, you are not allowed to make assignments between types. For example, the following is illegal:
int x = 1.1;
because the variable on the left is an int and the value on the right is a
double. But it is easy to forget this rule, especially because there are
places where C++ automatically converts one type to another. For example:
double y = 1;
should technically not be legal, but C++ allows it by converting the int to
a double automatically. This leniency is convenient, but it can cause
problems; for example:
double y = 1 / 3;
You might expect the variable y to be given the value 0.333333, which is a
legal floating-point value, but in fact it will get the value 0.0. The reason
is that C++ does integer division on the two integers before automatically
converting the resulting value (0 in this case) to a double, 0.0.
One way to solve this problem is to make the right-hand side a floating-point expression:
double y = 1.0 / 3.0;
This sets y to 0.333333 as expected.
All the operations we have seen - addition, subtraction, multiplication, and division - work on floating-point values, although you might be interested to know that the underlying mechanism is completely different. In fact, most processors have special hardware just for performing floating-point operations.
3.2. Converting between types¶
C++ converts ints to doubles automatically because no information is lost in
the translation. Going from a double to an int, on the other hand,
requires truncating and lost of information.
Depending on your compiler settings, your C++ compiler will probably allow this implicit conversion to occur without warning, but information will be lost in the process.
double pi = 3.14159;
int n = pi;
cout << n << endl;
This code will print 3, since the implicit conversion from a double to
an int resulted in loss of information. Converting from a double to an
float can also result in lost precision, as can other conversions from
larger memory data types to smaller memory ones.
Sometimes you want this to happen and you want to explicitly inform the compiler – and programmers reading your code – of your intention that it should. C++ supports explicit conversion using a type cast. Type casting is so called because it allows you to take a value that belongs to one type and “cast” it into another type (in the sense of molding or reforming, not throwing).
There are two different syntaxes for type casting in C++:
double pi = 3.14159;
int x = int(pi);
int y = (int)pi;
cout << x << ' ' << y << endl;
This will print 3 3, since both x and y will have the truncated
value 3. The first typecast uses the more modern C++ style, with syntax
similar to a function call. The second uses the older C style typecast. Both do
the same thing. Converting to an integer always truncates, even if the
fractional part is 0.999999.
For every type in C++, there is a corresponding function that typecasts its argument to that type (as long as there is a logical way to do that).
If we want to use a char variable to store small integers, and we want
to print its numeric, not its ASCII value, we can just typecast it to an
int:
char x = 65;
cout << "int(x) will print the number we want, " << int(x);
cout << ", instead of the character \"" << x << "\"," << endl;
cout << "which we don't want." << endl;
Put this in a complete program, compile it and run it. Notice the use of an
escape sequence, \",
to refer to the literal character ". This is needed because " is used to
mark the beginning and end of a string.
3.3. Math functions¶
In mathematics, you have probably seen functions like sin and log, and
you have learned to evaluate expressions like sin(π/2) and log(1/x).
First, you evaluate the expression in parentheses, which is called the
argument of the function. For example, π/2 is approximately 1.571, and
assuming x is 10, 1/x is 0.1.
Then you can evaluate the function itself, either by looking it up in a table or by performing various computations. The sin of 1.571 is 1, and the log of 0.1 is -1 (assuming that log indicates the logarithm base 10).
This process can be applied repeatedly to evaluate more complicated expressions
like log(1/sin(π/2)). First we evaluate the argument of the innermost
function, then evaluate the function, and so on.
C++ provides a set of built-in functions that includes most of the mathematical operations you can think of. The math functions are invoked using a syntax that is similar to mathematical notation:
double result = log(17.0);
double angle = 1.5;
double height = sin(angle);
The first example sets result to the logarithm of 17, base e. There is also
a function called log10 that finds logarithms base 10.
The second example finds the sine of the value of the variable angle. C++
assumes that the values you use with sin and the other trigonometric functions
(cos, tan) are in radians. To convert from degrees to radians, you can divide
by 360 and multiply by 2π.
If you don’t happen to know π to 15 digits, you can calculate it using the
acos function. The arccosine (or inverse of cosine) of -1 is π, because the
cosine of π is -1. The following program converts 90 degrees to radians:
#include <iostream>
#include <cmath>
using namespace std;
int main()
{
double pi = acos(-1.0);
double degrees = 90;
double angle = degrees * 2 * pi / 360.0;
cout << "Our angle measures approximately " << angle << " radians." << endl;
return 0;
}
Run this program and look at its output.
Before you can use any of the math functions, you have to include the math header file. Header files contain information the compiler needs about functions that are defined outside your program. So to use the math functions, you need to include the statement:
#include <cmath>
at the beginning of your program.
3.4. Composition¶
Just as with mathematical functions, C++ functions can be composed, meaning you can use one expression as part of another. For example, you can use any expression as an argument to a function:
double x = cos(angle + pi/2);
This statement takes the value of pi, divides it by two and adds the result
to the value of angle. This sum is then passed as an argument to the
cos function.
You can also take the result of one function and pass it as an argument to another:
double x = exp(log(10.0));
This statement finds the log base e of 10 and then raises e to that power. The result gets assigned to x; so what should it be?
3.5. Random numbers¶
Most computer programs do the same thing every time they are executed, so they are said to be deterministic. Usually, determinism is a good thing, since we expect the same calculation to yield the same result. For some applications, though, we would like the computer to be upredictable. Games are an obvious example.
Making a program truly nondeterministic turns out to be not so easy, but there are ways to make it at least seem nondeterministic. One of them is to generate pseudorandom numbers and use them to determine the outcome of the program. Pseudorandom numbers are not truly random in the mathematical sense, but for our purposes, they will do.
C++ provides a function called rand that generates pseudorandom numbers.
It is declared in the header file cstdlib, which contains a variety of
standard library functions, hence its name.
The return value from rand is an integer between 0 and RAND_MAX, where
RAND_MAX is a large number (about 2 billion on our system) also defined in
the header file. Each time you call rand you get a different pseudorandom
number. To rand in action, compile and run this program:
#include <cstdlib>
#include <iostream>
using namespace std;
int main()
{
cout << "RAND_MAX is: " << RAND_MAX << endl;
cout << "Let's generate 3 random numbers." << endl;
cout << "Random number 1: " << rand() << endl;
cout << "Random number 2: " << rand() << endl;
cout << "Random number 3: " << rand() << endl;
return 0;
}
Now try running the program again several times. What do you notice? You get the same set of 3 random numbers each time!
If we want our numbers to vary on program runs, we can set a random seed
for the pseudorandom number function rand by calling srand (for
“seed rand”). The srand function takes an integer argument. With a
different argument to srand, rand generates a different sequence of
numbers.
A common way to give srand a “random” seed is to use the time function,
which returns the current time in seconds.
Note
The time function returns
Unix time, which is the number
of seconds elapsed since January 1, 1970.
To use srand this way, we include the ctime header file and seed it
with the current time:
srand(time(NULL));
which will cause rand to generate a different sequence of numbers.
Here is a modified version of the previous program incorporating these changes:
#include <cstdlib>
#include <ctime>
#include <iostream>
using namespace std;
int main()
{
cout << "RAND_MAX is: " << RAND_MAX << endl;
cout << "Let's seed the rand() function with the time... ";
srand(time(NULL));
cout << "Done.\nNow let's generate 3 random numbers." << endl;
cout << "Random number 1: " << rand() << endl;
cout << "Random number 2: " << rand() << endl;
cout << "Random number 3: " << rand() << endl;
return 0;
}
Of course, we don’t usually want to work with gigantic integers. More often we want to generate integers between some lower bound and some upper bound. We will leave this as an exercise in the next chapter after we learn about the Modulus operator.
3.6. Adding new functions¶
So far we have only been using the functions that are built into C++, but it is
also possible to add new functions. Actually, we have already seen one
function definition: main. The functions named main is special because
it indicates where the execution of the program begins, but the syntax for
main is the same as for any other function definition:
TYPE NAME(LIST OF PARAMETERS)
{
STATEMENTS
}
You can make up any name you want for your function, except you can’t call it
main or any other C++ keyword. The list of parameters specifies what
information, if any, you have to provide in order to use (or call) the new
function.
main doesn’t have any parameters, as indicated by the empty parenthese
() in its definition. The first couple of functions we are going to write
also have no parameters, as well as a new keyword, void, used with
functions that do not return a value.
void new_line()
{
cout << endl;
}
This function is named new_line; it contains only a single statement, which
outputs a newline character, represented by the special value endl.
Our main function has return type int, which explains the statement:
return 0;
that we have avoided discussing until now. We’ll have a lot more to say about
the return statement shortly.
In main we can call our new_line function using syntax that is similar
to the way we call built-in C++ commands:
#include <iostream>
using namespace std;
void new_line()
{
cout << endl;
}
int main()
{
cout << "First Line." << endl;
newLine();
cout << "Second Line." << endl;
return 0;
}
Notice that new_line appears above the place where it is called (in
main). This is necessary in C++; the definition of a function must
appear before (above) the first use (call) of the function.
The output of this program is:
First Line.
Second Line.
Notice the extra space between the two lines. What if we wanted more space between the lines? We could call the same function repeatedly:
int main()
{
cout << "First Line." << endl;
new_line();
new_line();
new_line();
cout << "Second Line." << endl;
return 0;
}
Or we could write a new function, name three_lines, that prints three new
lines:
void three_lines()
{
new_line(); new_line(); new_line();
}
int main()
{
cout << "First Line." << endl;
three_lines();
cout << "Second Line." << endl;
}
You should notice a few things about this program:
You can call the same function repeatedly. In fact, it is quite common and useful to do so.
You can have one function call another function. In this case,
maincallsthree_linesandthree_linescallsnew_line. Again, this is common and useful.In
three_lineswe wrote three statements on the same line, which is syntactically legal (remember that spaces and new lines usually don’t chnage the meaning of a program). On the other hand, it is usually a better idea to put each statement on a line by itself, to make your program easy to read. We sometimes break that rule in order to save space.
So far, it many not be clear why it is worth the trouble to create all these new functions. Actually, there are a lot of reasons, but this example only demonstrates two:
Creating a new function gives you an opportunity to name a group of statements. Functions can simplify a program by hiding a complex computation behind a single command, and by using English works in place of arcane code. which is clearer,
new_lineorcout << endl?Creating a new function can make a program smaller by eliminating repetative code. For example, a short way to print nine connective new lines is to call
three_linesthree times. How would you pring 27 new lines?
3.7. Function calls and order of execution¶
When you look at a program that contains several functions, it is tempting to read it from top to bottom, but that is likely to be confusing, because that is not the order of execution of the program.
Execution always begins at the first statement of main, regardless of where
it is in the program (often it is at the bottom). Statements are executed one
at a time, in order, until you reach a function call. Function calls are like
a detour in the flow of execution. Instead of going to the next statement, you
go to the first line of the called function, execute all the statements there,
and then come back and pick up where you left off.
That sounds simple enough, except that you have to remember that one function
can call another. Thus, while we are in the middle of main, we might have
to go off and execute the statements in three_lines. But while we are
executing three_lines, we get interrupted three times to go off and execute
new_line.
Fortunately, C++ is adept at keeping track of where it is, so each time
new_line completes, the program picks up where it left off in
three_lines, and eventually gets back to main so the program can
terminate.
What’s the moral of this sordid tale? When you read a program, don’t read from top to bottom. Instead, follow the flow of execution.
3.8. Parameters and arguments¶
Some of the built-in functions we have used have parameters, which are
values that you provide to let the function do its job. For example, if you
want to find the sine of a number, you have to indicate what the number is.
Thus, sin takes a double value as an argument.
Some functions take more than one argument, like pow, which takes two
doubles, the base and the exponent.
Notice that in each of these cases we have to specify not only how many paramenters there are, but also what type they are. So it shouldn’t surprise you that when you write a function definition, the parameter list indicates the type of each parameter. For example:
void print_twice(char phil) {
cout << phil << phil << endl;
}
This function takes a single argument, named phil, that has type char.
Whatever that value is (and at this point we have no idea what it is), it gets
printed twice, followed by a newline. We chose the name phil to suggest
the name you give a parameter is up to you, but in general you want to choose
something more illustrative than phil.
In order to call this function, we have to provide a char. For example,
we might have a main function call like this:
int main() {
print_twice('a');
return 0;
}
The char value you provide is called an argument, and we say that the
argument is passed to the function. In this case the value 'a' is
passed as an argument to print_twice, where it will get printed twice.
Alternatively, if we had a char variable, we could use it as an argument
instead:
int main() {
char argument = 'b';
print_twice(argument);
return 0;
}
Notice something very important here: the name of the variable we pass as an
argument (argument here) has nothing to do with the name of the parameter
(phil). Let us say that again:
The name of the variable we pass as an argument has nothing to do with with the name of the parameter.
They can be the same or they can be different, but it is important to realize
they are not the same thing, except that they happen to have the same value
(in this case the letter 'b').
The value you provide as an argument must have the same type as the parameter of the function you call. This rule is important, but it is sometimes confusing because C++ sometimes converts arguments from one type to another automatically. You will have a chance to explore this behavior in the exercises. For now you should learn the general rule, and we will explain the exceptions later.
3.9. Parameters and variables are local¶
Parameters and variables only exist inside their own functions. Within the
confines of main, there is no such thing as phil. If you try to use it,
the compiler will complain. Similarly, inside print_twice ther is no such
thing as argument.
Variables like this are said to be local. In order to keep track of parameters and local variables, it is useful to draw a stack diagram. Like state diagrams, stack diagrams show the value of each variable, but the variables are contained in larger boxes that indicate which function they belong to.
For example, the stack diagram for print_twice looks like this:
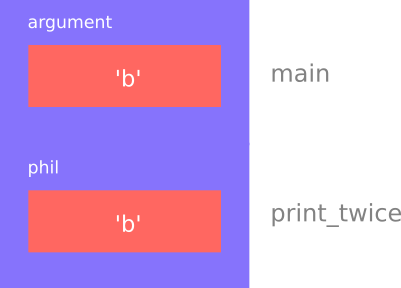
Whenever a function is called, it creates a new instance of that function. Each instance of a function contains the parameters and local variables for that function. In the diagram an instance of a function is represented by a box with the name of the function on the outside and variables and parameters inside.
In the example, main has one local variable, argument, and no
parameters. print_twice has no local variables and one parameter, named
phil.
3.10. Functions with multiple parameters¶
The syntax for declaring and invoking functions with multiple parameters is a common source of errors. First, remember that you have to declare the type of every parameter. For example:
void print_time(int hour, int minute) {
cout << hour << ":" << minute;
}
It might be tempting to write (int hour, minute), but that format is only
legal for variable declarations, not for parameters.
Another common source of confusion is that you do not have to declare the types of arguments. The following is wrong!
int hour = 11;
int minute = 59;
print_time(int hour, int minute); // WRONG!
In this case, the compiler can tell the type of hour and minute by
looking at their declarations. It is unnecessary and illegal to include the
type when you pass them as arguments. The correct syntax is
print_time(hour, minute).
3.11. Functions with results¶
You might have noticed by now that some of the functions we are using, like the
math functions, yield results. Other functions, like new_line, perform an
action but don’t return a value. That raises some questions:
What happens if you call a function and you don’t do anything with the result (i.e. you don’t assign it to a variable or use it as part of a larger expression)?
What happens if you use a function without a result as part of an expression, like
new_line() + 7?Can we write functions that yield results, or are we stuck with things like
new_lineandprint_twice?
The answer to the third questions is “yes, you can write functions that return values,” and we’ll see how to do that in the Fruitful functions chapter. We will leave it to you to answer the other two questions by trying them out in the exercises.
Any time you have a question about what is legal or illegal in C++, a good way (the best way) to find out is to ask the compiler.
3.12. Glossary¶
- argument¶
A value that you provide when you call a function. The value must have the same type as the corresponding parameter.
- call¶
A programming statement that causes a function to be executed.
- floating-point¶
A type of variable (or value) that can contain fractions as well as integers. There are a few floating-point types in C++; the one we use in this book is
double.- function¶
A named sequence of statements that performs some useful process. Functions may or may not take arguments, and may or may not produce a result.
- initialization¶
A statement that declares a new variable and assigns a value to it at the same time.
- parameter¶
A name for a value that will be provided to a function when it is called. Parameters are like variables in the sense that they contain values and have types.